Do we need a framework to manage parameters ?
If you work with parameterized notebooks in Databricks, typically your notebook would start with the below code blocks
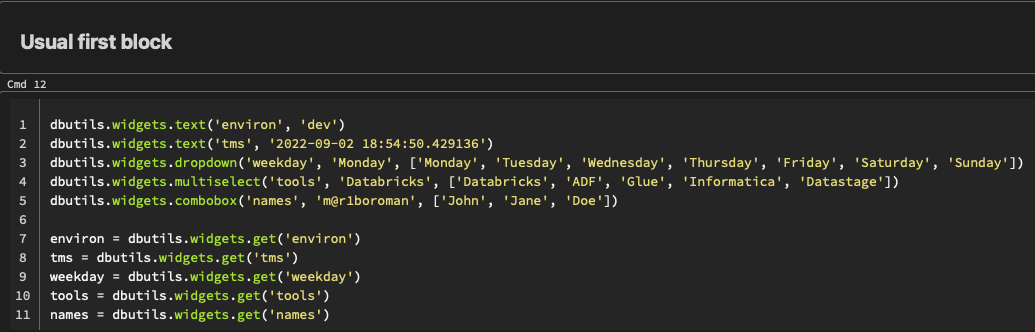
The size of this block grows considerably as the number of parameters increase
Although this approach is perfectly fine and is probably preferred for quick changes, I would recommend using the below framework for some specific reasons. Especially if you are building a framework for your ETL pipelines using databricks notebooks
- Consistency : If you are trying to manage hundreds of ETL Spark jobs all in separate notebooks, there is a good chance different developers use different parameter names for the same purpose. For e.g. developer A may use ‘env’ to store environment information and developer B may use ‘envion’ variable for the same purpose. This decreases the overall readability of the codebase.
- Less Code : The functions described below just need to be setup once preferably in any common library your project uses. Once done, its easy to invoke and use the parameters
TL;DR
Download the below notebook here with comments from the blog.
OR
View this notebook on github here
This notebook has been tested on Databricks Community Edition
Difference in parameters and variables in Databricks
Parameters are values sent to the Databricks notebooks usually from an external source. Say you are running a databricks notebook from Azure Data Factory or Amazon Glue, the values required to run the notebook dynamically (e.g. environment configurations) are typically sent as parameters
Variables are placeholders for data defined inside the notebook. For example, if language of choice is python, then the variables defined would be python variables.
Does it matter inside the notebook?
If you are using %sql magic command to define sql cells, the SQL cells would only be able to use the parameters and not the variables
An workaround for this situation would be to use the spark.sql(f-string) instead of the %sql magic command to create a dataframe using a dynamic SQL Query
Assumptions and Usage
Please note that the types defined in parameter_config MUST be one of (text, dropdown, multiselect, combobox) (Which are the supported widgets for databricks)
You could also make the code better by possibly defining Parameter class/type in python and make sure the functions accept only Parameter type, but for purposes of this blog we would keep it simple
Step 1 : Define the parameter_config list
# Format :
# [
# ('type_of_widget', 'parameter_name', 'parameter_default_value', 'additional_options (None for widget type text)'),
# ...
# ]
from datetime import datetime
parameter_config = [
('text','environ','dev',None),
('text','tms',datetime.now(),None),
('dropdown','weekday','Monday',['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']),
('multiselect','tools','Databricks',['Databricks', 'ADF', 'Glue','Informatica','Datastage']),
('combobox', 'names', 'm@r1boroman', ['John','Jane','Doe'])
]
Step 2: Define functions
Note that the below functions can be placed in a seperate notebook and can be used as common functionality across all the notebooks
def widget_generator_commands(config):
return [
f"dbutils.widgets.{widgettype}('{name}', '{default}')"
if widgettype == 'text'
else f"dbutils.widgets.{widgettype}('{name}', '{default}', {options})"
for widgettype, name, default, options in config
]
def widget_reader_commands(config):
return [
f"{name} = dbutils.widgets.get('{name}')"
for widgettype, name, default, options in config
]
def print_params(config):
for widgettype, name, default, options in config:
print(f"{name} = {eval(name)}")
Step 3: Execute functions
widget_generator_commands(config)
This function would return a list of commands to generate the widgets for given parameter_config
widget_reader_commands(config)
This function would return a list of commands to generate variables and assign them values from their respective widgets
print_params(config)
This function would display the parameter name and its corresponding value for all the parameters defined in parameter_config
# Create widgets
for creator in widget_generator_commands(parameter_config):
exec(creator)
# Read from widgets
for reader in widget_reader_commands(parameter_config):
exec(reader)
# Print all parameters
print_params(parameter_config)
Step 4? : Cleanup
dbutils.widgets.removeAll()